


The “Brute Force Aesthetics” of 0.9B
In an era where graphics cards are more expensive than gold, if you tell an investor you’ve built a 0.9B (less than one billion parameters) model, they might think you’re joking—or making a toy.
But PaddleOCR-VL-1.5 is like that small guy in the gym who builds functional strength. He might not have the exaggerated muscle definition of a bodybuilding champion (trillion-parameter models), but in a real fight—especially one rolling around in the mud—he actually wins.
On the latest OmniDocBench v1.5 leaderboard, this little guy achieved a 94.5% accuracy rate. The interesting part isn’t just the number, but the price-performance ratio. It uses almost stingy computational resources to accomplish what previously required a server cluster.
This is essentially a “correction” of the technical roadmap. Over the past two years, we’ve been too superstitious about “scaling laws,” thinking that as long as the parameters are large enough, dirty work like OCR (Optical Character Recognition) would solve itself. The result? Large models can write Shakespearean sonnets but often fail to correctly read a crumpled shopping receipt from the supermarket.
The emergence of PaddleOCR-VL-1.5 essentially tells the industry: Stop with the fluff. Refining and mastering document parsing is stronger than anything else.
The Real World Filtered Out by “Beauty Mode”
In this update, what excites me most as a “data neat freak” is actually something called Real5-OmniDocBench.
It sounds academic, but translated into plain English, it means: Five scenarios containing genuine human suffering.
Previous OCR benchmarks were mostly “flowers in a greenhouse”—perfectly flat PDFs scanned by scanners, black text on white paper, as clear as fresh textbooks. But in reality, the invoice your finance team pastes is crooked, your meeting whiteboard is covered in glare from the lights, and the contract you snapped a photo of is not only curved but has the shadow of your finger on it.
The PaddleOCR team did something particularly “stubborn” this time: instead of competing on who scores higher on clean data, they specifically competed on “bad” data.
- Scanning (Scanning Artifacts): Noise spots on aged documents.
- Warping: Paper that looks like it was crumpled into a ball and then smoothed out.
- Screen-photography: Moiré patterns from taking photos of computer screens.
- Illumination: Uneven lighting and strong reflections.
- Skew: Crooked and twisted shooting angles.
This image demonstrates the “hardcore” scenarios in the Real5 benchmark: complex formulas mixed into distorted pages. This is what the real world looks like, not a sterile laboratory environment.
Refreshing the SOTA (State of the Art) in these scenarios is much harder than improving 0.1% on a clean dataset. This shows the model is no longer rote-memorizing pixel arrangements but has started to possess a “robustness” similar to human vision—even if the text is crooked or blurry, it can make a highly accurate guess based on context and geometric shapes.
Especially with the introduction of irregular shape localization, specifically targeting polygon detection for curved documents. It’s like equipping the model with eyes that can “auto-correct”; whether you look at it lying down or upside down, the text remains the text.
The “Democratization” of Hardware
Talking about models without talking about deployment is just empty talk.
Look at the hardware support list for PaddleOCR-VL this time: putting aside aristocratic cards like NVIDIA, the key is that it has organized a circle of friends for domestic hardware—Huawei Ascend (NPU), Kunlunxin (XPU), Hygon (DCU), and even Apple Silicon.
What does this mean? It means the spring of Edge Computing has arrived.
Previously, for high-precision document parsing, data had to be uploaded to the cloud, which was not only slow but also involved privacy security (who wants to upload sensitive official documents to a public cloud?). Now, with 0.9B parameters and native support for various NPUs, you can run SOTA-level recognition on an ordinary domestic office computer or even a high-performance industrial control box.
This is the “democratization” of technology. It is no longer a patent for big companies with H100 clusters but has become a hammer available to every developer. Whether it’s a grassroots office in Tibet (Tibetan support was specifically added this time) or a trading port in Bangladesh (Bengali added), it can run locally.
This is what an open-source project should look like: Not picky eaters; setting up a home wherever there is a need.
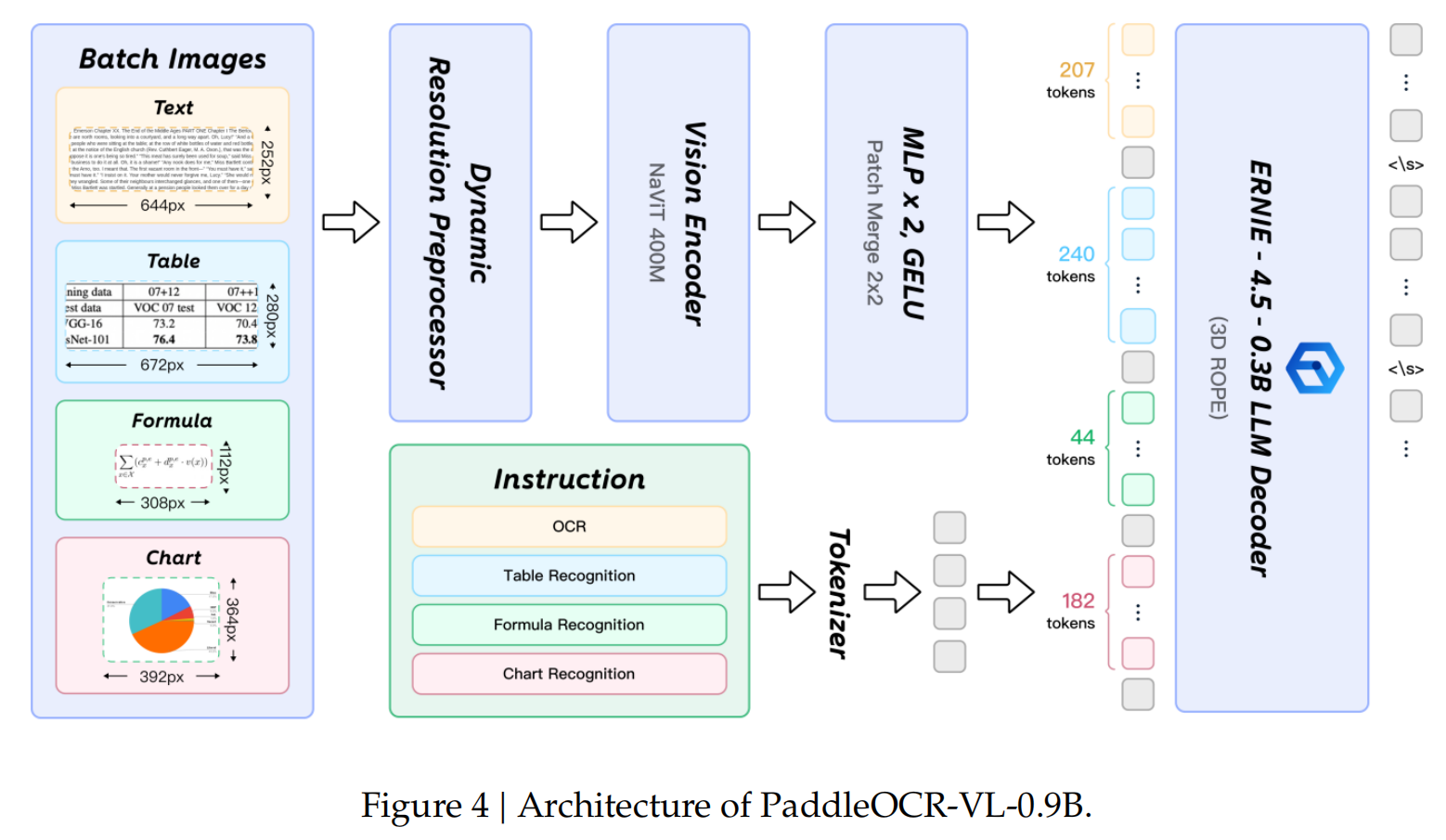
From left to right, in that seemingly chaotic flowchart, we see data being hit with a “dimensionality reduction strike”: even complex tables and seals are dismantled into machine-readable structured Tokens.
“Seeing” is Just the First Step
Of course, let’s not overhype it. No matter how strong PaddleOCR-VL-1.5 is, it currently solves problems at the “perception” level.
Although attempts like PP-ChatOCRv4 have been added to try and bridge the last mile from “recognition” to “understanding,” we all know that a 0.9B brain capacity is limited. Being able to precisely extract numbers, seals (the newly added seal recognition is indeed stunning), and table lines from a financial statement and turn them into structured Markdown is already an immense merit.
As for understanding whether the numbers behind these involve money laundering, or if the stamped contract carries legal risks, that is a job for the smarter “brain” behind it. PaddleOCR’s current role is more like an extremely reliable “Super Secretary”—it’s not responsible for decision-making, but it ensures that the materials handed to the Boss (Large Model) do not have a single error.
My only worry is, as the model’s capabilities expand (image editing, translation, recognition), will it become increasingly bloated? The current 0.9B is a perfect balance point; I hope future v2.0 and v3.0 versions won’t lose this rare lightness in pursuit of being “all-powerful.”
Working Quietly Amidst the Noise
If another AI company released a new version, there would likely be a press conference with lights and sound, shouting slogans about “reshaping the future.” But this PaddleOCR update is more like an engineering nerd’s late-night Commit—no nonsense, just substance.
In this restless start of 2026, we’ve seen too many disruptions on PPT slides. Looking back, what truly changes our lives are often these inconspicuous underlying technologies.
The next time you successfully scan an invoice for reimbursement in seconds on your phone, or find the paragraph you wanted in a scanned ancient book full of creases, remember to thank this little 0.9B guy. It doesn’t have the wisdom of a hundred billion parameters, but it has a pair of eyes striving to see the truth clearly in this chaotic world.
Sometimes, seeing the world clearly is much harder, and much more important, than reconstructing the world through imagination.