

兄弟们,如果你还在为了训练一个猫狗分类器,苦哈哈地去网上爬几万张图,然后一张张手动打标签,那我只能说:大人,时代变了。
不管是做内容审核、以图搜图,还是搞现在火得发紫的 AI 绘画,传统的计算机视觉(CV)开发流程简直就是个无底洞:数据清洗能洗掉你半条命,模型训练能烧掉你半年的显卡预算。最绝望的是,如果你突然想加个“仓鼠”分类,对不起,模型重训,流程重来。
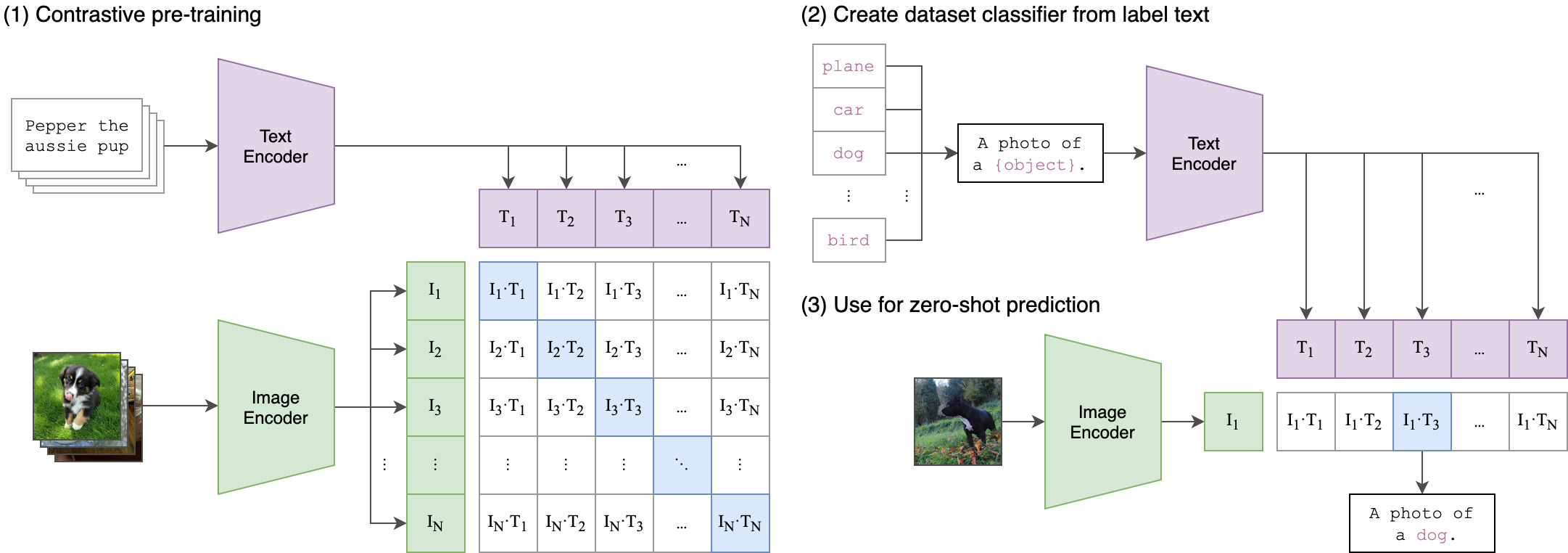
今天给你们安利的是 OpenAI 发布的封神之作——CLIP。这玩意儿的出现,基本上就是对着传统的 CV 领域来了一发“降维打击”。它不讲武德地把自然语言处理(NLP)和计算机视觉(CV)强行按头结婚了,让你不用训练就能识别万物。
废话不多说,硬核干货直接上。
核心亮点:能听懂人话的视觉模型
CLIP 全称是 Contrastive Language-Image Pre-Training(对比语言-图像预训练)。听起来很学术?没关系,你只需要记住一点:它学会了把图片和文字映射到同一个空间里。
1. Zero-Shot 能力堪比开挂
这是 CLIP 最骚的操作。以前的 ResNet 只能识别它训练集里有的那 1000 种东西。CLIP 不一样,它阅读了互联网上 4 亿对(图片+文本)的数据。
这意味着什么?意味着你不需要给它任何训练数据,直接问它:“这张图里是猫还是狗?”它就能告诉你答案。官方测试显示,CLIP 在 ImageNet 上的“零样本”表现,直接持平了经过全量监督训练的 ResNet-50。不给数据还能考满分,这找谁说理去?
2. 文本就是最好的分类器
在 CLIP 的架构里,分类不再是冷冰冰的 class_id: 0 或 1。你可以把分类标签变成一句话,比如 a photo of a dog 或者 a diagram of a circuit。
CLIP 包含两个编码器:
* Image Encoder:看图,提取特征。
* Text Encoder:读字,提取特征。
它计算图片特征和文本特征的余弦相似度。谁的得分高,就是谁。这种机制极大地提升了模型的泛化能力。你甚至可以用来做表情包搜索,输入“我都想笑了”,它能精准匹配那个表情。
3. 极其灵活的 API 设计
OpenAI 的代码风格一向简洁。CLIP 提供了非常简单的 Python 接口,几行代码就能完成模型加载、预处理和推理。它不仅能做分类,还是现在所有 AI 生成绘画(如 Stable Diffusion)的“鉴赏家”——它负责判断生成的图和提示词到底像不像。
竞品对比:CLIP 还是老大吗?
虽然 CLIP 是开山鼻祖,但在这个卷得飞起的 AI 圈,挑战者从没断过。我们来看看它和几个“当红炸子鸡”的硬碰硬对比。
1. OpenAI CLIP vs. OpenCLIP
这俩名字听着像,其实有大区别。OpenAI 的 CLIP 虽然开源了代码和模型权重,但训练数据并没有完全公开。
OpenCLIP 是社区(LAION 等)搞出来的“复仇者联盟”。
* 优势:OpenCLIP 使用了更大的公开数据集(如 LAION-5B),并且训练了比 OpenAI 还要大的模型(比如 ViT-G/14)。在某些特定领域的精度上,OpenCLIP 的大模型版本其实已经超越了 OpenAI 原版。
* 劣势:模型太大,显存杀手。如果你只是想快速上线一个轻量级应用,OpenAI 原版 ViT-B/32 依然是性价比之王,生态支持最好,Hugging Face 上随便调。
2. OpenAI CLIP vs. Google SigLIP
Google 搞的 SigLIP (Sigmoid Loss for Language Image Pre-Training) 是另一个强力对手。
* 技术差异:CLIP 用的是 Softmax 损失函数,这在处理海量数据时效率会有瓶颈。SigLIP 换成了 Sigmoid 损失,允许模型在更小的 Batch Size 下训练,效率更高。
* 实际体验:SigLIP 在多语言理解上通常更强一些,但 OpenAI CLIP 的英文图文匹配依然是“工业标准”。大多数现成的向量数据库和搜索工具,默认都是无脑兼容 OpenAI CLIP 的。
结论:如果你是搞科研或者追求极致精度,去卷 OpenCLIP;如果你是搞工程落地,追求稳定和生态,OpenAI CLIP 依然是那个最稳的“老大哥”。
部署与使用:这代码也太短了
部署 CLIP 不需要你配置复杂的训练环境,只要有 PyTorch 就行。
1. 安装
甚至不需要去 Clone 仓库,直接 pip:
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git
2. 三行代码搞定零样本分类
下面这个 Demo 展示了如何让 CLIP 自动识别图片里是“图表”、“狗”还是“猫”。
import torch
import clip
from PIL import Image
# 1. 自动检测是跑在 GPU 还是 CPU 上
device = "cuda" if torch.cuda.is_available() else "cpu"
# 2. 加载模型,这里选个平衡的 ViT-B/32
model, preprocess = clip.load("ViT-B/32", device=device)
# 3. 准备图片和文本
# 图片:读取 -> 预处理 -> 加 Batch 维度 -> 扔进设备
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
# 文本:把你想分类的标签写成句子,CLIP 会自动 Tokenize
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
# 4. 计算图文相似度
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs)
# 输出结果大概率是: [[0.99, 0.00, 0.00]] -> 99% 是图表
你看,完全不需要训练过程。你把 ["a diagram", "a dog", "a cat"] 换成 ["hotdog", "not hotdog"],它立马就变成硅谷美剧里的那个热狗识别器,连一秒钟都不用等。
结语
CLIP 的出现证明了一件事:暴力美学是真的管用。大数据+大算力+多模态,直接把传统的“小作坊式”模型训练按在地上摩擦。
对于我们开发者来说,这绝对是好事。以前搞图像识别是炼丹,得看火候;现在有了 CLIP,直接变成了搭积木。无论你是想做个智能相册,还是想搞个以文搜图的搜索引擎,CLIP 都是你绕不开的那座大山。
别看了,赶紧去 GitHub 把它 Clone 下来,感受一下什么叫“听懂人话”的视觉模型。
项目地址: https://github.com/openai/CLIP